
First steps of AI
Most of us were not likely to have been present to witness the inception of the term 'artificial intelligence', which dates back to 1956, sparked in the hallowed halls where the Dartmouth Conferences took place. The event, held at Dartmouth College in Hanover, New Hampshire, heralded a groundbreaking moment where a small group of scientists, including Marvin Minsky, John McCarthy, and Allen Newell, convened to explore the possibilities of machines not just calculating but simulating aspects of human intelligence. They proposed that a machine could be made to mimic cognitive processes, navigating through problems, learning, and even language understanding, by maneuvering symbols in a manner akin to human reasoning. This was not just a technical meeting but a pivotal point where the seeds of an idea that machines could think - at least in some capacity - were sown.
So at its core AI, or artificial intelligence, possesses the ability to carry out tasks typically associated with human intelligence, such as learning or problem-solving. This artificial intelligence is categorized into two parts depending on its design focus: if it's crafted to solve only one 'intelligent' problem, such as playing chess, we refer to it as Narrow AI; or if it’s designed to manage a suite of complex problems that typically only a human could handle, which might be ideally exemplified by the robots from the animated movie WALL-E; this kind is referred to as General AI. Currently, we are not there yet.
Today, AI is steamrolling our market, but in the fifties, it wasn’t quite like that. With its introduction, a wave of optimism arose, which, however, subsided due to insufficient technological progress, finances, and interest from large companies of those times. Back then, we only had a theory, which failed to successfully develop for several more decades. Subsequently, a rapid development in the field of Machine Learning breathed new life into AI.
Breakthrough of machine learning
Machine learning, operating as a subset of artificial intelligence, enjoyed its initial surge of prominence during the 1980s. It involves utilizing algorithms to analyze data, learn from it, and subsequently predict or determine an output value. To gain a better understanding of this process, let’s visualize it together in the following diagram.

Let's learn by a simple example together. Imagine a scenario where you find yourself on the sinking Titanic. You can gauge your chances of surviving the disaster based on the outcomes experienced by others. So, if 50% of children survived the catastrophe and the overall mortality rate was 95%, you would have a significantly higher chance of survival if you were a child. Several attributes influence the outcome, but you will not define the process through which it operates. Narrow AI defines itself based on whether a person with particular attributes has survived or not. This is referred to as machine learning, where the machine learns the resulting algorithm on its own. The more data you provide, the better and more proficient it can be.
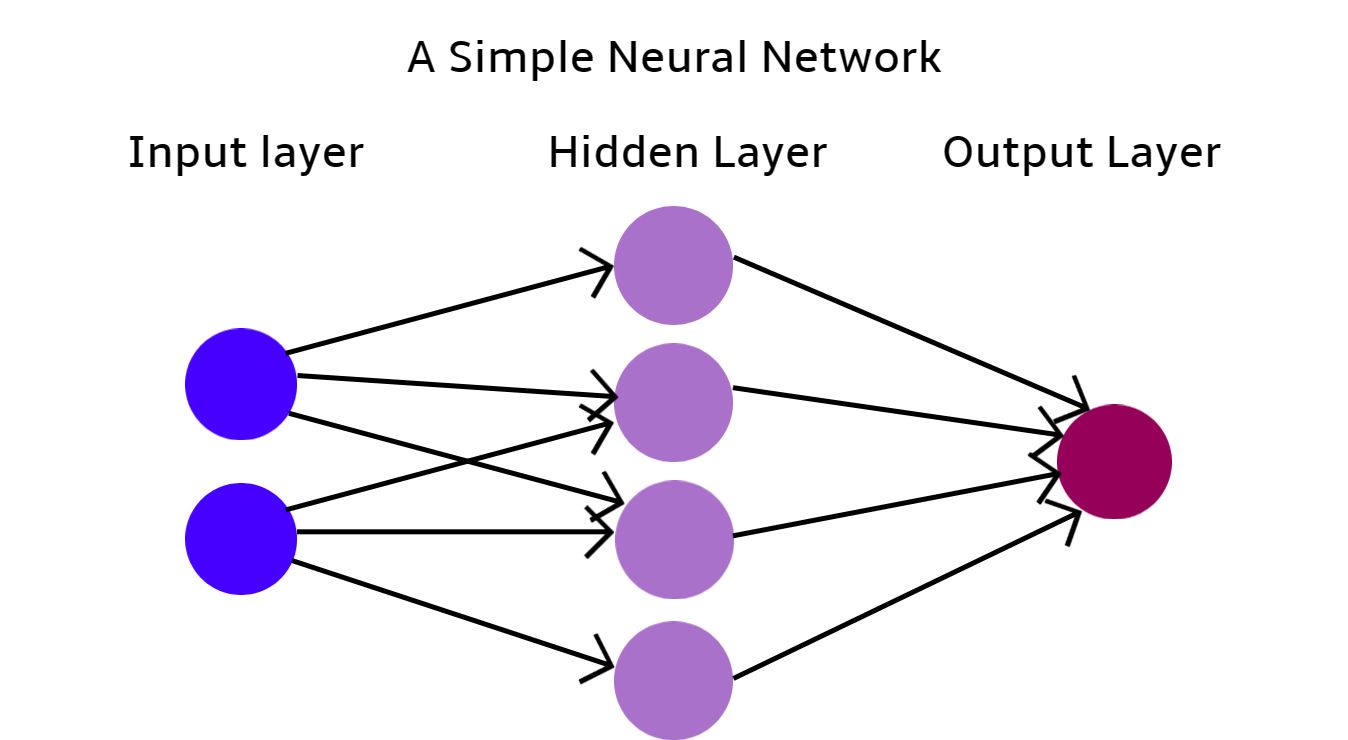
Neural network - machine learning in practice
We understand the theory of machine learning and recognize its emergence from artificial intelligence (AI). But how do we practically implement this theory? The answer lies in neural networks.
Is the term 'neural networks' familiar to you? Perhaps because we, too, have neurons in our brains, which have inspired the development of neural networks.
Imagine a scenario where you’re leisurely sitting in your backyard, sipping coffee, and observing the sky. You spot something moving above, and your brain identifies it as a bird, based on its shape, movement, and color. These characteristics —shape, movement, and color— act as input parameters that your neurons process. With these, your brain, through an undisclosed process, determines that what you’re observing is a bird. Neural networks operate upon a similar principle. This form of AI leverages machine learning by utilizing pre-established models. When the input parameters are provided, much like in the human brain, the model helps you recognize that you're observing a bird soaring through the sky.

This example we have just introduced would utilize a previously-created neural network, but just as our brains were trained to learn after we were born, a neural network also must learn. This way, we can then use its trained model through machine learning.
We could visualize the process of creating such a simple neural network as follows:
- Choosing the Appropriate Training Data
Selecting relevant data is crucial for what we seek to develop, ensuring it is free from anomalies and superfluous attributes. Generally, a more voluminous dataset leads to a higher-quality output model. Including more relevant attributes allows for a more personalized, though potentially more complex, model. Importantly, data must be normalized.
- Selecting the Model Architecture
The critical task of selecting the correct neural network architecture often hinges on the specific applications of your model, such as generating images or text. The choice of architecture plays a substantial role in the performance and efficacy of the model in performing its designated task.
- Training the Selected Model
Data is bifurcated into training and testing sets. Training data aids the model in formulating an algorithm, which endeavors to predict the outcome attribute based on input parameters. If predictions falter, the algorithm adapts, iteratively refining itself until it begins to make accurate predictions.
- Testing the Final Model
The model is then exposed to the testing data, attempting to predict their resultant parameter. If the predictive accuracy achieves a satisfactory success rate, the model is ready for deployment. If not, further adjustments to the model will be necessary.
Let’s use our knowledge in practice with this sample example made using Python.
Embarking on a Model Development for Heart Attack Prediction
We were tasked with creating a model aimed at predicting heart attacks, provided with a dataset that we diligently optimized. Here’s how the outcome has unfolded:
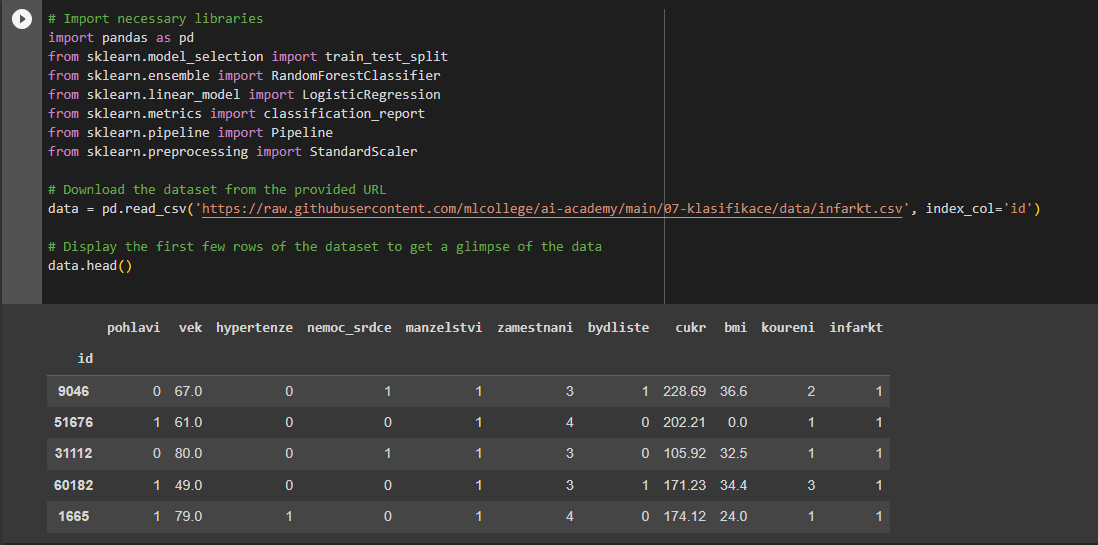
- Reviewing the Data Header
First and foremost, we reviewed the header of the data to ensure everything was in order, paving the way to dive into the data preparation process. The attributes are in Czech because we used a local dataset from ML College.
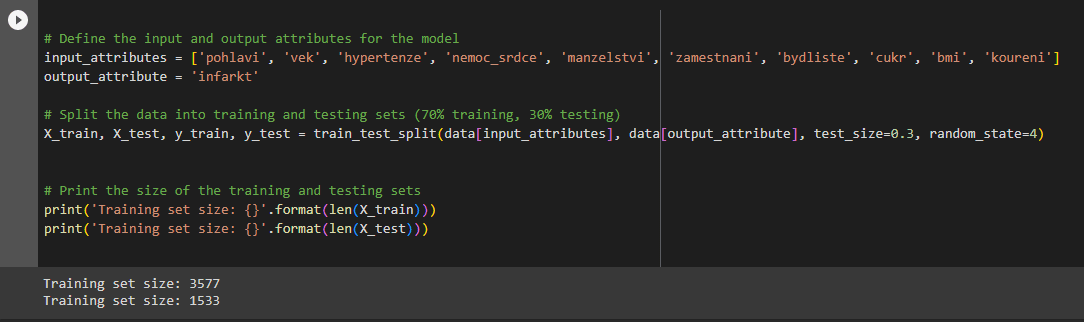
- Data Segmentation into Training and Testing Subsets
This crucial step ensures our model learns from one data subset and is validated against another, unseen subset to gauge its predictive prowess.
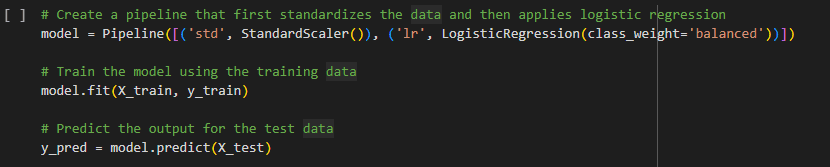
- Model Definition, Training Data Insertion, and testing of the Trained Model
A model was defined, into which the training data was fed, laying the foundation for the system to learn and formulate predictive algorithms.
- Loading Testing Data and Displaying Model Statistics
If the model performs satisfactorily, measured by the statistics and predictive accuracy determined during the testing phase, it is primed for real-world application. Satisfaction is tethered to the model's statistical outcomes, elucidating its precision and depicted in the latter section of the final image.
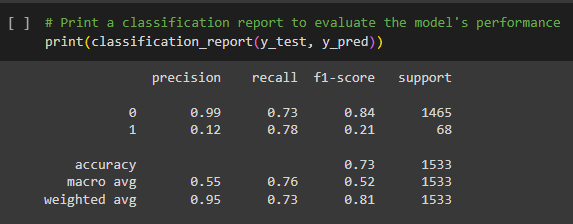
Let's unpack the meaning behind these statistical values:
- Precision: In all of the instances which were flagged as positive by the model, how many truly were positive?
- Recall: From all of the actual positive instances, how many were correctly identified by the model?
- F1 Score: Representing the harmonic mean of precision and recall, a high F1 Score points to both high precision and recall.
- Support: Reflects the actual number of instances of each class within the data.
The Evolution from Simple Neural Networks to Deep Learning
Simple neural networks were used prevalently until around the year 2010 when more advanced technologies and supercomputers with significantly higher computational capacities became available. However, a challenge emerged: up until this period, only sequential models had been used, which struggled to process large amounts of data as they could only handle one piece of information at a time. A group led by Geoffrey Hinton from the University of Toronto was conscious of this problem and managed to parallelize the algorithms of neural networks.
Geoffrey Hinton, who also worked for Google, witnessed his discovery being utilized by his colleague Andrew Yan-Tak Ng. Andrew constructed a massive neural network on Google’s computer, loaded it with data from 10 million images from YouTube videos, and set it to detect whether images of cats were present. The robustness of this neural network lent the term Deep Learning its name, which can be defined as follows:
“Deep learning is a method in artificial intelligence (AI) that teaches computers to process data in a manner inspired by the human brain. Deep learning models can recognize complex patterns in pictures, text, sounds, and other data to produce accurate insights and predictions.”
Simply put, these are highly complex neural networks with multiple layers.
Thanks to deep learning, a new era of artificial intelligence has started, called Generative artificial intelligence.
The Digital Assistant of the Future - GAI
Generative AI encompasses a suite of artificial intelligence technologies that can create content. It can generate new, previously unseen inputs derived from the patterns in the data upon which it was trained. Unlike discriminative models that predict or classify incoming data based on learned patterns, generative models can generate new data points, thus offering a diverse array of applications.
Picture this: You're wrestling with a challenging assignment. Instead of spending hours toiling over it, you pass it along to an adept "friend" who swiftly identifies the errors and suggests revisions. Or, perhaps you're planning to whip up a gourmet meal but can't recall all the ingredients. Again, this "friend" comes to your rescue, furnishing you with the perfect recipe based on what you have currently in your kitchen. This omnipresent, ever-helpful friend isn't a person; it's a manifestation of AI, meticulously trained to streamline and enrich various facets of our daily lives.
Among the most illustrious incarnations of Generative AI today are text chatbots. These digital entities craft responses based on textual prompts. The process is seamless: launch a web browser, navigate to your chatbot of choice and key in a query. Thanks to their extensive training on diverse internet data, chatbots can grasp a wide array of topics, even deciphering intricate, bespoken requests. Consequently, they respond with the expertise and nuance one might expect from a human specialist. In the rapidly evolving landscape of AI, chatbots represent just the tip of the iceberg, heralding a future where our interactions with technology will have become more intuitive and personalized.
How is it possible to create generative AI?
Large Language Models (LLMs) serve as immensely sophisticated tools rooted in artificial intelligence, specifically engineered to comprehend, interpret, and generate textual content in a manner that mimics human communication. By ingesting and analyzing vast amounts of textual information, these models learn the intricacies and nuances of language, allowing them to generate coherent, contextually relevant responses and create content that can be remarkably indistinguishable from that written by a human.
When we interact with an LLM, it processes our input (the text we provide) and, based on its extensive training, produces a response that is not only syntactically correct but also semantically meaningful. This means it understands the structure of language and can also grasp the meaning behind the words. Whether you’re asking a question, seeking information, or needing assistance in generating text, the LLM sifts through its learned knowledge to provide relevant and coherent outputs.
Moreover, LLMs can be applied across a myriad of applications, including but not limited to, generating textual content, answering queries, creating written content, and even assisting in more creative tasks such as composing poetry or stories. The versatility and adaptability of LLMs have positioned them as invaluable assets in numerous domains, such as customer support, content creation, and conversational agents, bridging the gap between technological interaction and human-like dialogue.
With a foundational understanding of Artificial Intelligence (AI), and having explored the intricacies of machine learning, neural networks, and other pivotal technologies, our sights are firmly set on the horizons of Generative Artificial Intelligence (GAI).
Future of GAI in DecisionRules
At DecisionRules, our commitment to innovation and enhancement propels our active engagement in developing new features to augment our rule engine software. Future iterations of our offerings will be designed to seamlessly integrate artificial intelligence, ensuring we harness the myriad of possibilities it unfolds. For those interested in accompanying us on our GAI journey, stay tuned for our next upcoming article on AI, where we will delve deeper into the specific applications of artificial intelligence within the DecisionRules ecosystem.
Stay tuned for more!

Jan Viktor Krepelka
Developer