The Problem With Opaque AI Outputs
Imagine your AI returns a risk score of 64 and a recommendation to escalate for manual review. Your compliance officer asks: what drove that score? Which part of the application triggered the flag? How confident was the model?
Without Explainable AI, the answer is: you do not know. The model processed the input and returned a number. The reasoning stayed inside the model.
This is not an academic problem. This matters in regulated industries like lending, insurance, procurement, and healthcare, where decisions must be defensible. An output nobody can explain is an output nobody can stand behind.
What Explainable AI Adds to Every Result
When Explainable AI is enabled it automatically attaches an explanation object to every response. You do not configure it, define it, or prompt for it. It is generated by the model at execution time and returned alongside your regular output fields.
The object contains four pieces of structured information:

Probability
A confidence score from 0 to 1. Close to 1 means the model had clear, explicit evidence. Lower values signal inference or ambiguity.

Reason
A plain-language paragraph walking through how the model arrived at each output field, including what was stated directly vs. what had to be inferred.

Source fragments
The exact phrases or sentences from the input the model used to determine its output. Copied verbatim from the source document or data.

Warnings
Plain-language flags for any output field the model filled with less than full confidence because input was ambiguous, estimated, or had to be read between lines.
---
Together these four fields give a complete picture: what the model concluded, how confident it was, where in the source it found each value, and where it had to make a judgment call.
Available as Part of the AI Agent
Explainable AI is a built-in capability of the DecisionRules AI Agent . It is activated with a single toggle in the rule designer so no custom prompting, no additional configuration, no separate tool to connect.
Once enabled, the explanation fields are part of the rule's output model and flow through Decision Flows like any other output. They can be read by downstream rules, logged to your audit systems, displayed in review interfaces, or used as routing conditions all within the same workspace where the rule lives.
Turning Confidence Into an Automated Routing Decision
The confidence score is not just a number to log, it is a routing signal.
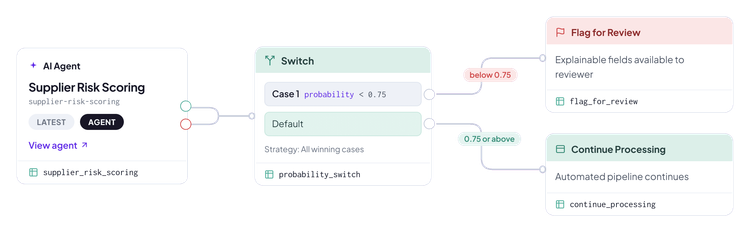
A single confidence threshold splits the flow into automatic approval and manual review.
The threshold you choose depends entirely on your use case and acceptable risk. A procurement validation might accept a 0.80 threshold. A lending decision in a regulated market might require 0.95. The point is that you set the threshold deliberately, based on business judgment, and the system routes accordingly.
Where Explainable AI Makes a Real Difference
The value of the explanation object shows up most clearly in workflows where a wrong answer is expensive and a human still has to sign off.

Credit and risk scoring
Surfaces exactly which applicant fields were uncertain or missing before a decision is made.
Risk teams know where to focus

KYC and onboarding
Low-confidence outputs are routed to a human automatically, with the reasoning already attached.
Cuts time-to-decision on edge cases

Compliance checks
Produces an audit-ready narrative for each decision, written when the decision was made.
No developer needed to reconstruct it

Contract review
Shows exactly which clause triggered a flag, so reviewers jump straight to the relevant section.
No re-reading the whole document
---
In each of these, a different field does the heavy lifting:
- warnings expose what the model was unsure of
- probability score decides what gets escalated
- reason field writes the audit trail
- source fragments point a reviewer to the exact text
What It Means for Your Organization
| Concern | Without Explainable AI | With Explainable AI |
|---|---|---|
| Audit trail | Output exists. Reasoning does not. | Every decision carries a structured explanation generated at the moment it was made. |
| Manual review quality | Reviewers re-read entire documents to understand what triggered a flag. | Reviewers receive the exact source fragments and a plain-language summary of model reasoning. |
| Low-confidence handling | All outputs treated equally regardless of how certain the model was. | Uncertain outputs are automatically identified and routed differently based on a defined threshold. |
| Regulatory defensibility | Difficult to explain an AI-assisted decision to a regulator or stakeholder. | The reason field provides a written, human-readable justification for each output. |
| Business user oversight | Non-technical teams cannot verify whether AI outputs match policy intent. | Compliance and operations teams can read and validate the reasoning without engineering support. |
Why This Changes the Decision, Not Just the Output
The shift Explainable AI makes is small to switch on but large in consequence. The model still does the hard work of reading and reasoning, but now it shows that work in a form your team and your systems can use. A score becomes a score with a reason behind it. A flag becomes something a reviewer can act on in seconds. An audit request stops being a scramble to reconstruct what the model was thinking and becomes a matter of reading a field that was written at the moment the decision was made.
That is what separates an AI output you tolerate from one you can stand behind. For any decision that has to answer to a regulator, a customer, or your own risk team, the explanation is not a nice extra. It is the part that makes the automation safe to trust.
And because it is built into the AI Agent rather than bolted on afterward, you get it by enabling a toggle, not by building a second system to watch the first.

Ivan Peresta works at DecisionRules, where his role spans product analysis, professional services, and customer support. He is involved across the full lifecycle of product features, from early design and UX thinking to hands-on testing, documentation, and customer-facing delivery. His work bridges the gap between product development and the people who actually use it, whether that means helping a customer design their rule system or making sure a new feature ships with clear guidance and working examples.