El problema de los resultados opacos de la IA
Imagina que tu IA devuelve un puntaje de riesgo de 64 y una recomendación para escalar a revisión manual. Tu oficial de cumplimiento pregunta: ¿qué impulsó ese puntaje? ¿Qué parte de la solicitud activó la alerta? ¿Qué tan seguro estaba el modelo?
Sin IA explicable, la respuesta es: no lo sabes. El modelo procesó la entrada y devolvió un número. El razonamiento se quedó dentro del modelo.
Este no es un problema académico. Importa en industrias reguladas como el otorgamiento de préstamos, el seguro, la contratación pública y la atención de salud, donde las decisiones deben ser defendibles. Una salida que nadie puede explicar es una salida que nadie puede respaldar.
Qué agrega la IA explicable a cada resultado
Cuando se habilita la IA explicable, adjunta automáticamente un objeto de explicación a cada respuesta. No se configura, no se define ni se solicita mediante un prompt. Lo genera el modelo en el momento de la ejecución y se devuelve junto con tus campos de salida habituales.
El objeto contiene cuatro piezas de información estructurada:

Probabilidad
Una puntuación de confianza de 0 a 1. Cuanto más cerca de 1, significa que el modelo tuvo evidencia clara y explícita. Los valores más bajos señalan inferencia o ambigüedad.

Razonamiento
Un párrafo en lenguaje sencillo que explica cómo el modelo llegó a cada campo de salida, incluyendo qué se indicó directamente vs. qué tuvo que inferirse.

Fragmentos de origen
Las frases o oraciones exactas del contenido de entrada que el modelo utilizó para determinar su salida. Copiado literalmente del documento o los datos fuente.

Advertencias
Señales en lenguaje sencillo para cualquier campo de salida que el modelo completó con menos que confianza plena, porque la entrada era ambigua, estimada o tuvo que leerse entre líneas.
---
Juntos, estos cuatro campos ofrecen una imagen completa: qué concluyó el modelo, qué tan seguro estaba, dónde encontró cada valor en la fuente y en qué punto tuvo que emitir un juicio.
Disponible como parte del agente de IA
La IA explicable es una capacidad incorporada de la DecisionRules AI Agent . Se activa con un solo interruptor en el diseñador de reglas, así que no hay prompts personalizados, no hay configuración adicional y no hay una herramienta separada que conectar.
Una vez habilitadas, las secciones de explicación forman parte del modelo de salida de la regla y fluyen a través de Decision Flows como cualquier otra salida. Pueden ser leídas por reglas posteriores, registradas en tus sistemas de auditoría, mostrarse en interfaces de revisión o usarse como condiciones de enrutamiento, todo dentro del mismo espacio de trabajo donde vive la regla.
Convertir la confianza en una decisión de enrutamiento automatizada
La puntuación de confianza no es solo un número para registrar: es una señal de enrutamiento.
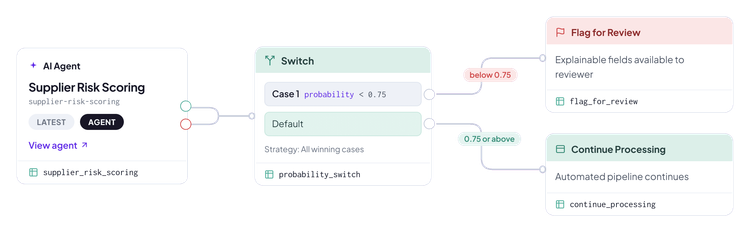
Un solo umbral de confianza divide el flujo entre aprobación automática y revisión manual.
El umbral que elijas depende por completo de tu caso de uso y del riesgo aceptable. Una validación de compras podría aceptar un umbral de 0.80. Una decisión de préstamo en un mercado regulado podría requerir 0.95. La idea es que establezcas el umbral de manera deliberada, con base en el criterio del negocio, y el sistema enrutará en consecuencia.
Dónde la IA explicable marca una diferencia real
El valor del objeto de explicación se ve con mayor claridad en flujos de trabajo donde una respuesta incorrecta es costosa y aun así una persona debe dar su aprobación.

Calificación de crédito y riesgo
Muestra con precisión qué campos del solicitante estaban inciertos o faltaban antes de que se tome una decisión.
Los equipos de riesgo saben en qué enfocarse

KYC y onboarding
Las salidas de baja confianza se envían automáticamente a un humano, con el razonamiento ya adjunto.
Reduce el tiempo de decisión en casos límite

Verificaciones de cumplimiento
Genera una narrativa lista para auditoría para cada decisión, escrita cuando se tomó la decisión.
No se necesita a ningún desarrollador para reconstruirla

Revisión de contratos
Muestra exactamente qué cláusula activó una alerta, para que los revisores vayan directo a la sección relevante.
No tener que releer todo el documento
---
En cada uno de estos, un campo distinto hace el trabajo pesado:
- las advertencias muestran en qué no estaba seguro el modelo
- el puntaje de probabilidad decide qué se debe escalar
- el campo de razonamiento escribe el rastro de auditoría
- los fragmentos de origen guían al revisor hacia el texto exacto
Qué significa para tu organización
| Preocupación | Sin IA explicable | Con IA explicable |
|---|---|---|
| Rastro de auditoría | La salida existe. El razonamiento no. | Cada decisión incluye una explicación estructurada generada en el momento en que se tomó. |
| Calidad de la revisión manual | Los revisores vuelven a leer documentos completos para entender qué activó una alerta. | Los revisores reciben los fragmentos exactos de origen y un resumen en lenguaje sencillo del razonamiento del modelo. |
| Manejo de baja confianza | Todas las salidas se tratan por igual, sin importar qué tan seguro estuvo el modelo. | Las salidas inciertas se identifican automáticamente y se enrutan de manera diferente según un umbral definido. |
| Defendibilidad regulatoria | Es difícil explicar una decisión asistida por IA a un regulador o a una parte interesada. | El campo de razón proporciona una justificación escrita y legible para humanos para cada salida. |
| Supervisión del usuario de negocio | Los equipos no técnicos no pueden verificar si las salidas de IA coinciden con la intención de la política. | Los equipos de cumplimiento y operaciones pueden leer y validar el razonamiento sin apoyo de ingeniería. |
Por qué esto cambia la decisión, no solo la salida
El cambio que habilita la IA explicable es pequeño para activarla, pero grande en sus consecuencias. El modelo sigue haciendo el trabajo difícil de leer y razonar, pero ahora muestra ese trabajo en una forma que tu equipo y tus sistemas pueden usar. Un puntaje se convierte en un puntaje con una razón detrás. Una alerta se convierte en algo en lo que el revisor puede actuar en segundos. Una solicitud de auditoría deja de ser una carrera por reconstruir lo que el modelo estaba pensando y pasa a ser un asunto de leer un campo que se escribió en el momento en que se tomó la decisión.
Eso es lo que separa una salida de IA que toleras de una que puedes respaldar. Para cualquier decisión que tenga que responder ante un regulador, un cliente o tu propio equipo de riesgo, la explicación no es un extra agradable. Es la parte que hace que la automatización sea segura para confiar en ella.
Y como está integrada en el Agente de IA en lugar de añadirse después, la obtienes al habilitar un interruptor, no construyendo un segundo sistema para supervisar el primero.

Ivan Peresta
Product Analyst