
Let’s be honest: performance bottlenecks are the silent killers of digital transformation
They don’t show up with a dramatic crash. They sneak in quietly masked as delayed dashboards, timeouts, sluggish rule flows, and the dreaded “Please wait…” just when things matter most. Performance is critical in every industry. Speed matters whether you’re in Financial Services, Insurance, Healthcare, E-Commerce, or Transport. Need to approve things faster? Do you need to price dynamically? Do you need to calculate across dozens of complex conditions in real time? High performance in your business processes isn’t just nice to have, it’s essential. When your business is moving fast, your decision engine has only one job:
Keep up and don’t break.
So we ran the tests. Not just a few smoke checks, but full-stack load simulations. We threw 600 virtual users at our logic engine. We benchmarked decision tables, trees, scripts, and rule flows across three different infrastructure tiers and we captured real logs every step of the way.
Because theory is cute, but performance is proof.
Before the Fun Stuff
There are two concepts we would like to explain before we dive deeper into it.
What’s a “worker”?
Think of a worker as the person doing the actual job. Every time your system needs to make a decision like calculating a price or checking eligibility a worker handles that task. The more workers you have, the more decisions you can process at once.
**What’s an “instance”?**
That’s just the computer (virtual or physical) where the workers live. You can have one worker on a computer, or multiple. You can also have multiple computers, each with their own workers.
Let’s Talk Numbers
Here’s how each tier performed per worker, per minute. (The Advanced tier used 2 workers, so total values per instance are doubled)
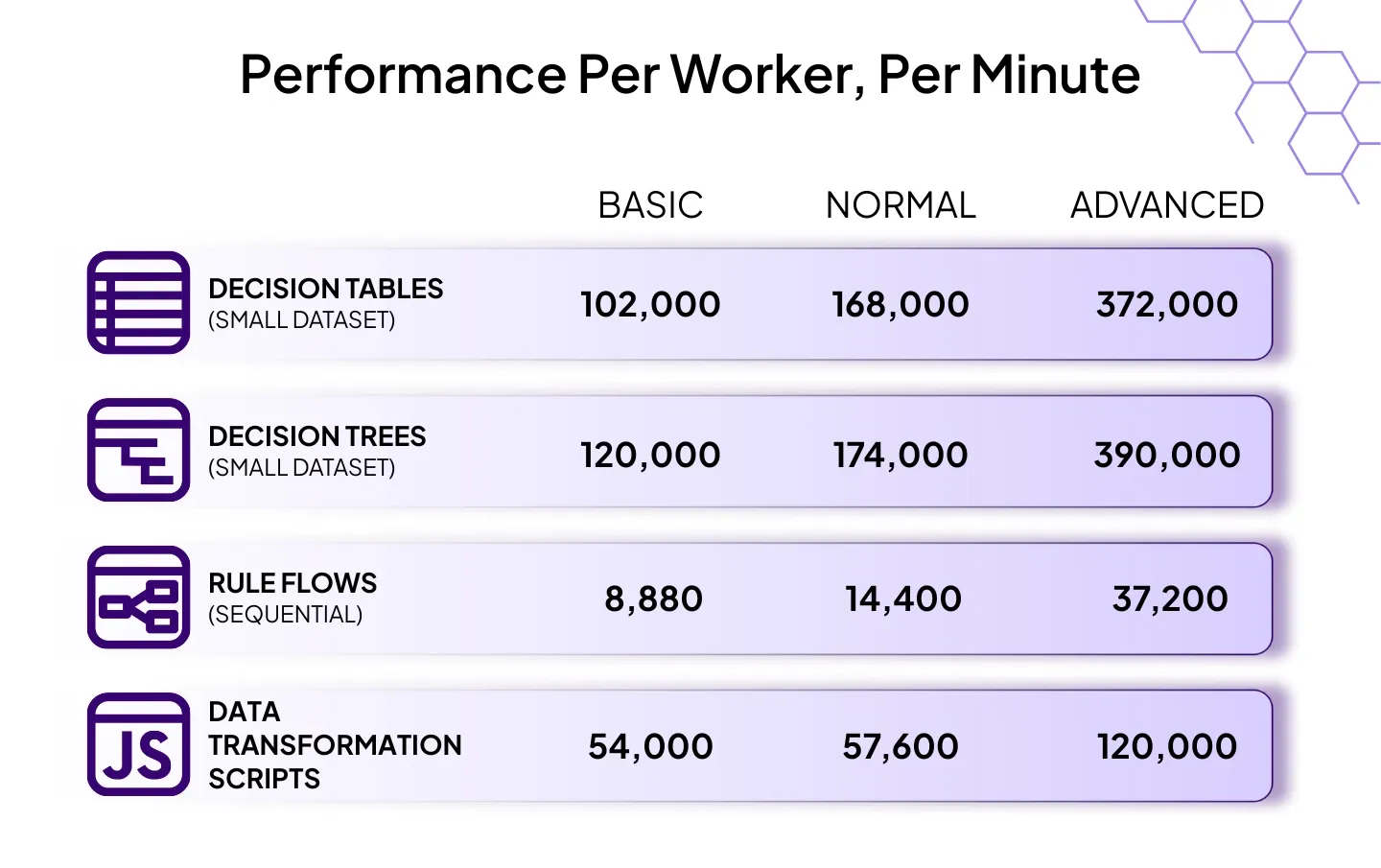
Even in our most demanding advanced-tier tests, complex rule flows ranged from 210-1000ms, while lightweight tables and trees consistently hit sub-20ms latency.
But not everything’s a tiny rule and at peak we processed over 39 million requests in 10 minutes without a single system-level failure.
What We Tested (And Why It Matters)
We modeled 3 realistic setups from basic configurations to production-ready environments to more accurately reflect the kinds of deployments businesses actually use.
But before we get into the test results, here are two terms you should be familiar with. I promise these are the last definitions you’ll have to read.
What’s “Redis”?
This is like a high-speed scratchpad. It helps the system quickly remember results it has already seen so it can answer repetitive questions much faster.
What’s “in-memory cache”?
It’s a way to keep frequently needed data right at the worker’s fingertips, instead of going out to get it again. It’s just like having your top 10 reports always open on your desk rather than stored in a filing cabinet.
Now that you know what’s going on under the hood, here is how we structured the three performance tiers we tested:
EC2 Tier Comparison
Tier
EC2 Type
Workers/Instance
In-Memory Cache
Redis Type
Basic
t4g.micro
1
Disabled
cache.t4g.micro
Normal
c7g.medium
1
Enabled
cache.t4g.micro
Advanced
c8g.large
2
Enabled
cache.m7g.large
We used m7i.2xlarge machines to simulate 600 users ramping up over 10 minutes.
The results? Fast, scalable, and stable. No matter how complex the logic or how heavy the load.
Speed Test: Decision Tables Built for Volume
To see how fast the system can go under pressure, we used a real-world pricing rule which is our product catalogue decision table. This is the kind of rule you would use in e-commerce or product configuration. It simulated high-volume price checks using real business logic.
Here’s what the engine handled at the Normal tier with 600 virtual users:

That’s over 3.1 million successful decisions with no failures and an average time under 60 milliseconds per request.
“This is the kind of speed you want behind pricing engines, configurators, and live API endpoints that are fast, predictable, and built to scale.”
Tough Rule Flows, No Sweat
We stress-tested something heavier “Parallel Auto-Approval Rule Orchestration”. This is a ruleset used to determine whether offers from financial institutions should be auto-approved or fall back to manual underwriting. The logic includes:
Differences between expected and offered APR
Whether certain funders need proof of income
Dynamic conditions like *“proof of income required”
*All done in parallel across 40+ funding sources
This isn’t a simple “if-then” case, it's real decision automation, driven by diverse parameters across funders, introducers, and end consumers.

That’s over 321,000 iterations, nearly 650,000 successful validations, and just 4 responses needed correction.
Even better? Monitoring tools failed (StatsD connection refused), but the logic engine didn’t skip a beat.
“Observability broke. The rule engine kept going. That’s the kind of stability that matters in production.”
Scaling Done Right
There’s a common myth: if performance is lagging, just throw a bigger machine at it. More CPUs! More power! More… problems.
Here’s what nobody tells you:
- 1 worker = 1 CPU core
You could spin up a giant 12-core instance. This is called vertical scaling and it does work… But it’s like hiring one person to do everything faster instead of building a team.
We prefer horizontal scaling:
- Instead of one big computer, use several small ones
- Each with its own dedicated job (or “worker”)
- If one slows down, the others keep going
1 instance with 1 worker for Basic and Normal and 2 workers for Advanced.
- Same total compute power
- Less contention
- Better fault tolerance
- Smoother scaling under load
This lets you grow from handling a few requests per minute to millions per hour with no dramatic infrastructure change.. The horizontal-first approach ensures DecisionRules grows with your needs. From hundreds of requests per minute to millions per hour with consistency and predictability baked in.
Production-Ready, No Surprises
We didn’t stop at ideal environments. We also tested older and lower-end setups:
Rule flows that once crashed at 300 users now run flawlessly at 600+
Decision tables that responded in 600 milliseconds now fire in **13 milliseconds
**Trees and tables with thousands of branches remain under 20 milliseconds at median at scale
Whether you’re using DecisionRules to power internal automations or customer-facing rule flows, you get predictable performance across environments.
Final Word: Predictable Performance, On Your Terms
We don’t just build a Business Rule Engine. We build a system that:
Empower analysts to edit logic in minutes without developer help
Scale confidently across use cases and traffic with zero downtime
Deliver even when parts of your system fail
Whether you’re automating discount engines, insurance pricing, commission models, or regulatory logic, DecisionRules is ready when your business needs it most.
Because when every decision counts your engine should, too.

Leon Moraes
Business Analyst